I thought I’d write about how fanriff.com serves its Ember.js index from its Sinatra.rb API, and how web clients interacts with the back-end once the application is loaded. It started to run a little long so I’ve broken it up into parts. This first chapter will cover some background information on Ember, the fanriff.com web architecture, and how we deploy our Ember index to our stack.
Contents
Single-Page Applications
Ember is an MVC framework for developing single-page applications. If you’re unfamiliar with the technology, an SPA is a JavaScript-based web app that runs entirely in the browser. Instead of HTML being rendered server-side and delivered to clients “over the wire,” as in a traditional web app, JavaScript retrieves JSON-encoded data from server-side APIs and renders the HTML client-side. SPAs have a lot of advantages over traditional web apps, such as:
- Site only “loads” once; actions taken by the user modify the DOM without triggering page refreshes
- Data is retrieved asynchronously via XMLHttpRequest (XHR) calls, and asynchronously-changing data can automatically update the DOM
- Interactivity and responsiveness more closely resemble the user experience enabled by “native” desktop and mobile apps (at least in theory)
- Computationally-expensive operations—such as sorting and filtering complex collections—burn the user’s CPU cycles instead of your own, making it easier and cheaper to scale to more users (although this can be considered a disadvantage for slower devices)
- Overall data transfer is less because a web client typically only needs to download the assets (images, scripts, templates, and stylesheets) once, at boot time, and JSON-encoded data is typically smaller than rendered HTML containing the same content
- Server-side APIs can be shared between web, iOS, Android, and other clients
It would take an awful lot of effort to implement features like background data refreshing, observers, and complex collection sorting and filtering in JavaScript. Fortunately, Ember, Ember CLI, and Ember Data take care of all of these concerns and more. Additionally, there is a vibrant ecosystem of plugins (Ember Addons) that can be added to your project to enable everything from data visualization to lightning fast deployment. I’ll be calling out a few specific addons in this post. You can see who’s using Ember and get an idea of its power and flexibility at builtwithember.io.
Of course, SPAs are not without their disadvantages. Since the app is running entirely client-side, in JavaScript, users have the ability to view (and modify!) their copy of the source code and any data retrieved from server-side APIs. Any proprietary logic should be executed server-side, and care must be taken not to send any data to the user you don’t want them to see. And although overall data transfer is less, web clients have to download more assets on the initial page load than your typical traditional web app.
Authentication is more challenging, and vulnerabilities like cross-site scripting (XSS) and cross-site request forgery (XSRF) take on subtle differences cf. traditional web apps. Session (and cookie) management, cross-origin resource sharing (CORS), and caching and deployment develop new wrinkles, and your deployment strategy necessarily becomes more complex as you now have to coordinate separate back- and front-end releases (unless you embed your SPA in your back-end, which comes with its own set of problems). And, of course, older web clients with limited JavaScript support (or modern web clients with JavaScript disabled) are not supported.
Our Architecture
 fanriff.com’s stack, simplified, looks something like this:
fanriff.com’s stack, simplified, looks something like this:
- HAproxy “Load Balancer”
- TLS termination
- DoS protection
- Load-balancing reverse proxy (to Varnish)
- Varnish “Web Application Accelerator”
- Content caching and compression
- Load-balancing reverse proxy (to Puma)
- Puma “Ruby Web Server”
- Rack application server
- Sinatra.rb RESTful APIs
Static assets (images, scripts, templates, and stylesheets), with the exception of the Ember index, are served via Amazon.com’s CloudFront content delivery network (CDN) from an S3 bucket. We use MariaDB and Memcached as our backing stores, but those are outside the scope of this write-up!
Ember, First Boot
Because the entire web application “boots” on the initial page load, it is critical that we serve the index page as quickly and securely as possible. The browser won’t start downloading assets and executing the JavaScript until the index is fully-loaded. The index also contains critical metadata that tells the browser 1. which assets are safe to load and 2. how to validate that the correct assets have been loaded. This first interaction between the client and our app establishes the trust mechanisms for the rest of the session (until the user forces a full page refresh), so it’s vitally important to get right.
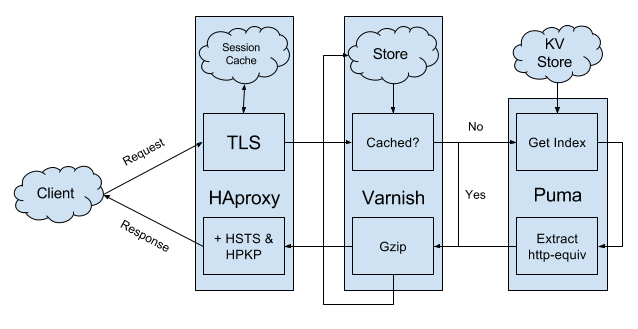
With that in mind, here is the request/response flow that fanriff.com implements to serve its index page:
- User requests fanriff.com, and the web client looks up the IP address of our edge and validates the TLS certificate
- If the user goes to http://fanriff.com, http://www.fanriff.com, or https://www.fanriff.com, our edge will redirect them to https://fanriff.com
- If the user has previously visited fanriff.com, the web client will know (via a previously-seen Strict-Transport-Security header) to only load the secure version of the site
- If the user has previously visited fanriff.com, the web client will know (via a previously-seen Public-Key-Pins header) to only accept certain TLS certificates
- Our edge serves up our certificate with a strict subset of TLS protocols and ciphers, a time-stamped OCSP response, protocol negotiation, and with TLS compression and session tickets disabled (for security reasons)
- Our edge also implements TLS session caching (to speed up subsequent requests), and basic DoS protection (to prevent our site from being easily overwhelmed by a bad actor)
- Our edge passes the request on to our caching layer, which rewrites the URI of the request to “/” (unless it’s an XHR call, which we’ll discuss in the next chapter), and looks to see if the Ember index is in its internal store
- If the user has previously visited fanriff.com, the web client will send a If-None-Match header on the request, and our caching layer will compare the value of this header to the cached content’s ETag and respond with a 304 status code if they match
- If it’s not available in its internal store, our caching layer passes the request on to an application server, which pulls the current Ember index out of an external key-value store and extracts any http-equiv meta tags to present as first-class response headers (we’ll discuss the why of all this in the next section)
- Our caching layer compresses the response and adds it to its internal store if it’s new, and inspects the Accept-Encoding header on the original request to determine if it should serve compressed or uncompressed content
- Our edge adds up-to-date Strict-Transport-Security and Public-Key-Pins headers to the outgoing response
Lightning-Fast Deployment
At this point, you’re probably wondering why on Earth we’re serving the index out of a key-value store. Why not treat it like any other asset and serve it from the CDN? Or why not serve it from Sinatra as a static page? Why go through all this rigamarole? Well, the reasons are pretty straightforward:
- We want to serve it from the same domain as the API
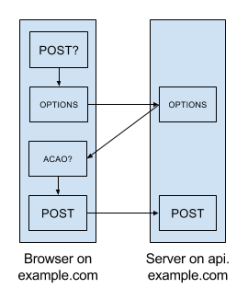
When you visit a site, its domain name becomes the “origin” for all future requests involving that site. Due to the web’s same-origin policy, certain restrictions apply if you try to make requests from one domain to another, e.g. from example.com to api.example.com (and yes, subdomains are considered different origins). Specifically, a non-GET, cross-domain XMLHttpRequest (XHR) call requires a preflight OPTIONS request that responds with an Access-Control-Allow-Origin (ACAO) header, and the header must include the origin (or a matching wildcard) attempting the call. This is called cross-origin resource sharing (CORS), and it’s no fun at all. Additionally, any cookies must be set with wildcard domains (e.g. “.example.com”) if you want to be able to access their contents from both the client and the server, which decreases cookie security and complicates traceability (i.e. it makes it more difficult to answer the question “what set this cookie?”).
 You can avoid the whole bugaboo by serving the index from the same domain as the API. You won’t need preflight OPTIONS requests or ACAO headers, and you can set a single, non-wildcard domain on your cookies. (We’ll still have to deal with CORS later to be able to load assets from our CDN, but we’re not making non-GET XHR calls to or setting cookies on the CDN so it’s much, much simpler.)
You can avoid the whole bugaboo by serving the index from the same domain as the API. You won’t need preflight OPTIONS requests or ACAO headers, and you can set a single, non-wildcard domain on your cookies. (We’ll still have to deal with CORS later to be able to load assets from our CDN, but we’re not making non-GET XHR calls to or setting cookies on the CDN so it’s much, much simpler.)
- We want to deploy it quickly and autonomously
“Fine, we’ll serve the index from the same domain as the API. But why not just serve it from Sinatra as a static page?” The short answer is that we don’t want to have to re-deploy the back-end every time there’s a new release of the front-end. This becomes especially problematic if you have a huge back-end with lots of tests and a hairy deployment process. There is an excellent video titled “Lightning Fast Deployment of Your Rails-backed JavaScript app” that features Luke Melia explaining this problem (and the genesis of ember-cli-deploy) in detail, and I can’t recommend it highly enough.
- We want to preview new versions before they go live, and easily revert if something goes wrong
Another benefit of having the Ember index and its past versions in a key-value store is that we can quickly and easily revert a change if something goes wrong, and we can stage future versions of it in there as well and preview them with a URL parameter.
- We want to present http-equiv meta tags as first-class response headers
Finally, there are some response headers that are managed by Ember and presented as http-equiv meta tags, but some of the features of these headers can only be enabled if they are presented as first-class response headers. Specifically, Ember can generate your Content-Security-Policy (or Content-Security-Policy-Report-Only) header and include it in your index as an http-equiv meta tag, but you can’t specify the report-uri or frame-ancestors directives in a meta tag, per the specification. This solution lets you have the best of both worlds: Ember manages it, and Ruby “upgrades” the meta tag(s) to real headers when serving the page. (We’ll talk more about Content-Security-Policy in the next chapter.)
This potentially opens up the ability for the front-end development team to manage other response headers, but with great power…
To sweeten the deal, the cost of achieving all of the above “wants” is quite minimal. We already have a big, beautiful stack for the API that includes TLS termination, caching, and a Ruby application server. Furthermore, Ember has a wonderful addon (and associated plugins) called ember-cli-deploy that works hand-in-hand with Ember’s build system to fully automate the process of deploying your assets to S3 (or other object stores) and your index to Redis (or other key-value stores). The documentation even includes sample Ruby (and Node.js) code for retrieving and serving the index; I’ve made my version, which includes logic to set the ETag and extract http-equiv meta tags, available in a Gist (and here’s one if you’re using MySQL instead of Redis). It doesn’t get any easier than this!
It’s worth listing in full at this point everything that Ember takes care of at deploy time; all you have to do (once you’ve configured your plugins) is type ember deploy production and you’re off:
- Compiling, minimizing, and compressing assets (your code and any third-party code you’ve imported into your application, including Ember itself)
- Fingerprinting assets (so multiple versions can coexist in S3, which plays nicely with the revert and preview feature discussed above)
- Rewriting assets so links to other assets include any CDN URL and reflect the fingerprinted filename (e.g.
<img src="https://example.cloudfront.net/assets/logo-0da0b89.pnginstead of<img src="assets/logo.png) - Uploading assets to S3
- Hashing the final script and stylesheet files and adding subresource integrity attributes to
<scriptand<linktags in the index page (we’ll talk more about subresource integrity in the next chapter) - Generating the Content-Security-Policy header and adding the http-equiv meta tag to the index page
- Uploading the new revision of the index page to Redis
- Optionally activating the new revision of the index page in Redis (or this can be done separately at a later time)
- Dispatching any notifications or other tasks important to your workflow (e.g. sending a message to a Slack channel or triggering cache invalidation)
Not to sound too much like I’ve drank the Kool-Aid, but it’s pretty amazing when it all comes together.
Next Steps
The web client has established trust mechanisms with our edge and obtained a copy of the index, and so it is free to continue booting the site, which includes the following steps:
- Validate the Content-Security-Policy
- Retrieve assets from the CDN with cross-origin resource sharing
- Validate script and stylesheet hashes against subresource integrity attributes
- Execute JavaScript and render the initial HTML
- Establish or resume a session (or something session-like) with the back-end
I’ll be covering these topics (as well as how XHR calls are routed through our stack) in the next chapter of this write-up. Thank you for reading, and please let me know in the comments if you have any questions!
Further Reading